Giám đốc MLCommons David Kanter đã đưa ra quan điểm rằng những cải tiến trong cả kiến trúc phần cứng và phần mềm học sâu đã dẫn đến những cải tiến về hiệu suất trên AI, gấp mười lần những gì được mong đợi từ chỉ cải tiến quy mô chip truyền thống. MLCommons
Google và Nvidia chia nhau điểm số cao nhất cho bài kiểm tra điểm chuẩn hai năm một lần về đào tạo chương trình trí tuệ nhân tạo, theo dữ liệu được công bố vào thứ Tư bởi MLCommons, hiệp hội ngành giám sát một bài kiểm tra phổ biến về hiệu suất học máy, MLPerf.
Kết quả đào tạo MLPerf phiên bản 2.0 cho thấy Google giành điểm số cao nhất về thời lượng thấp nhất để đào tạo mạng nơ-ron trên bốn tác vụ cho các hệ thống có sẵn trên thị trường: nhận dạng hình ảnh, phát hiện đối tượng, một bài kiểm tra cho hình ảnh nhỏ và một bài kiểm tra cho hình ảnh lớn, và mô hình xử lý ngôn ngữ tự nhiên BERT.
Nvidia đã giành được danh hiệu cao nhất cho bốn trong số tám bài kiểm tra, cho các hệ thống có sẵn trên thị trường của nó: phân đoạn hình ảnh, nhận dạng giọng nói, hệ thống đề xuất và giải quyết nhiệm vụ học tập củng cố khi chơi cờ vây trên tập dữ liệu “mini Go”.
Cũng thế: Kiểm tra điểm chuẩn về hiệu suất của AI, MLPerf, tiếp tục thu hút được nhiều tín đồ
Cả hai công ty đều có điểm số cao cho nhiều bài kiểm tra điểm chuẩn, tuy nhiên, Google không báo cáo kết quả cho các hệ thống thương mại cho bốn bài kiểm tra còn lại, chỉ cho bốn bài kiểm tra mà nó giành được. Nvidia đã báo cáo kết quả cho tất cả tám bài kiểm tra.
Các bài kiểm tra điểm chuẩn báo cáo mất bao nhiêu phút để điều chỉnh “trọng số” hoặc thông số thần kinh, cho đến khi chương trình máy tính đạt được độ chính xác tối thiểu cần thiết trên một nhiệm vụ nhất định, một quá trình được gọi là “đào tạo” mạng thần kinh.
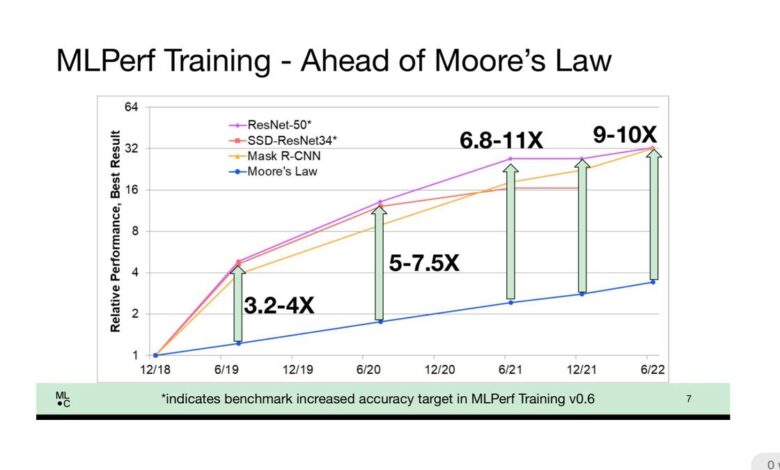
Trên tất cả các nhà cung cấp, thời gian đào tạo cho thấy những cải thiện đáng kể nhờ vào cả phương pháp tiếp cận phần mềm thông minh hơn và mã lực lớn hơn. Trong một cuộc họp báo với giới truyền thông, giám đốc điều hành của MLCommons, David Kanter giải thích rằng xét trên phạm vi rộng, kết quả cho thấy rằng quá trình luyện tập đã tăng hiệu suất tốt hơn Định luật Moore, quy tắc ngón tay cái truyền thống cho biết tốc độ bóng bán dẫn của chip tăng gấp đôi sau mỗi 18 đến 24 tháng. tăng hiệu suất máy tính.
Kanter cho biết ngày nay, điểm số trong nhiệm vụ ImageNet đáng kính, trong đó mạng nơ-ron được huấn luyện để gán nhãn phân loại cho hàng triệu hình ảnh, ngày nay nhanh hơn 9 đến 10 lần so với những cải tiến chip đơn giản.
Kanter nói: “Chúng tôi đã làm tốt hơn rất nhiều so với Định luật Moore. “Bạn sẽ mong đợi có được hiệu suất tốt hơn khoảng ba lần rưỡi, giả sử rằng các bóng bán dẫn có liên quan tuyến tính với hiệu suất; hóa ra, chúng ta đang nhận được Định luật Moore gấp 10 lần.”
Kanter, “nhà nghiên cứu với một máy trạm duy nhất” chỉ chứa 8 con chip, cho biết:
Nvidia, công ty thống trị doanh số bán chip GPU chiếm phần lớn hoạt động điện toán AI trên thế giới, thường xuyên gửi kết quả cho hầu hết hoặc tất cả các bài kiểm tra. Ông lưu ý rằng những máy trạm đơn lẻ đó đang có những cải tiến hoặc mở rộng quy mô bóng bán dẫn đơn giản từ 4 đến 8 lần. “Chúng tôi đang đặt nhiều khả năng hơn vào tay các nhà nghiên cứu, điều này cho phép chúng tôi thực hiện nhiều thử nghiệm hơn và hy vọng sẽ tạo ra nhiều khám phá hơn.”
Google, có TPU là một trong những đối thủ cạnh tranh chính của chip Nvidia, có thành tích kém nhất quán với MLPerf. Trong Báo cáo điểm chuẩn của tháng 12công ty chỉ gửi một số thử nghiệm, để sử dụng thử nghiệm TPU của mình trong thử nghiệm BERT.
Google cho biết trong các nhận xét chuẩn bị sẵn sàng, “TPU v4 của Google [version 4] Siêu máy tính ML thiết lập kỷ lục hiệu suất trên năm điểm chuẩn, với tốc độ trung bình là 1,42 lần so với lần gửi nhanh nhất tiếp theo không phải của Google và 1,5 lần so với lần gửi MLPerf 1.0 của chúng tôi. ”
Tham chiếu của Google về năm điểm chuẩn bao gồm điểm tốt nhất được báo cáo trên các hệ thống đề xuất cho một hệ thống nghiên cứu không có sẵn trên thị trường.
Khi được ZDNet hỏi tại sao Google lại chọn cạnh tranh với các hệ thống thương mại trong bốn danh mục chứ không phải bốn danh mục khác, công ty cho biết trong một phản hồi qua email, “Mục đích của chúng tôi với các bài nộp là tập trung chủ yếu vào khối lượng công việc tối đa hóa lợi ích ngoài MLPerf cho chúng tôi.
“Chúng tôi đưa ra quyết định về việc gửi mô hình nào dựa trên sự tương đồng của chúng với mô hình ML được sử dụng trong Google và bởi khách hàng của Google Cloud. Gửi và điều chỉnh điểm chuẩn là một khối lượng công việc đáng kể, vì vậy chúng tôi tập trung nỗ lực để tối đa hóa lợi ích ngoài MLPerf cho chúng tôi.
“Do đó, chúng tôi tập trung nỗ lực vào bốn điểm chuẩn cho danh mục Cloud có sẵn – BERT, ResNet, RetinaNet, MaskRCNN.”
Nvidia nhấn mạnh phạm vi toàn diện của các đệ trình bởi chính họ và bởi các đối tác bao gồm Dell và Lenovo. Máy tính sử dụng chip Nvidia thuộc loại này hay loại khác chịu trách nhiệm cho 105 hệ thống và 235 kết quả thử nghiệm được báo cáo trong tổng số 264 kết quả được báo cáo.
“NVIDIA và các đối tác của mình tiếp tục cung cấp hiệu suất đào tạo AI tổng thể tốt nhất và nhiều bài nộp nhất trên tất cả các điểm chuẩn với 90% tất cả các mục đến từ hệ sinh thái, theo điểm chuẩn MLPerf được công bố hôm nay”, giám đốc điều hành Nvidia, Shar Narasimhan cho biết trong các nhận xét chuẩn bị.
“Nền tảng NVIDIA AI bao gồm tất cả tám điểm chuẩn trong vòng MLPerf Training 2.0, làm nổi bật tính linh hoạt hàng đầu của nó.”
Cũng thế: MLCommons tiết lộ một cách mới để đánh giá siêu máy tính nhanh nhất thế giới
Trong số những phát triển khác, thử nghiệm MLPerf tiếp tục thu hút được nhiều người theo dõi và thu được nhiều kết quả thử nghiệm hơn so với trước đây. Tổng cộng có 21 tổ chức đã báo cáo kết quả kiểm tra 264, tăng từ 14 tổ chức và 181 tổ chức đã gửi báo cáo trong báo cáo phiên bản 1.1 tháng 12.
Những người mới tham gia bao gồm Asustek; Học viện Khoa học Trung Quốc, hoặc CASIA; nhà sản xuất máy tính H3C; HazyResearch, tên được gửi bởi một sinh viên tốt nghiệp; Krai, người đã tham gia cuộc thi MLPerf khác, suy luận, nhưng chưa bao giờ tập luyện trước đây; và khởi động MosaicML.
Trong số năm hệ thống thương mại hàng đầu, Nvidia và Google đã bị theo sau bởi một số ít người gửi đã cố gắng đạt được vị trí thứ ba, thứ tư hoặc thứ năm.
Đơn vị đám mây Azure của Microsoft đã giành vị trí thứ hai trong cuộc thi phân đoạn hình ảnh, vị trí thứ tư trong cuộc thi phát hiện đối tượng với hình ảnh có độ phân giải cao và vị trí thứ ba trong cuộc thi nhận dạng giọng nói, tất cả đều sử dụng hệ thống với bộ xử lý AMD EPYC và GPU Nvidia.
Nhà sản xuất máy tính H3C đã giành vị trí thứ năm trong bốn bài kiểm tra, cuộc thi phân đoạn hình ảnh, cuộc thi phát hiện đối tượng với hình ảnh có độ phân giải cao, công cụ đề xuất và chơi trò chơi cờ vây, và cũng có thể giành vị trí thứ tư trong nhận dạng giọng nói. Tất cả các hệ thống đó đều sử dụng bộ xử lý Intel XEON và GPU Nvidia.
Dell Technologies giữ vị trí thứ tư về phát hiện vật thể với hình ảnh có độ phân giải thấp hơn và vị trí thứ năm trong bài kiểm tra ngôn ngữ tự nhiên BERT, cả hai đều với các hệ thống sử dụng bộ xử lý AMD và GPU Nvidia.
Nhà sản xuất máy tính Inspur đã giành vị trí thứ năm về nhận dạng giọng nói với hệ thống sử dụng bộ xử lý AMD EPYC và GPU Nvidia, đồng thời giữ vị trí thứ ba và thứ tư trong các hệ thống khuyến nghị, tương ứng với các hệ thống dựa trên XEON và EPYC.
Cũng thế: Graphcore mang đến sự cạnh tranh mới cho Nvidia trong các điểm chuẩn MLPerf AI mới nhất
Graphcore, công ty khởi nghiệp tại Bristol, Anh xây dựng máy tính với phương pháp tiếp cận phần mềm và chip thay thế, chiếm vị trí thứ năm trong ImageNet. Nhà cung cấp giải pháp CNTT Nettrix đã giành vị trí thứ tư trong cuộc thi phân đoạn hình ảnh và vị trí thứ tư trong thử thách học tăng cường cờ vây.
Trong một cuộc họp báo dành cho các nhà báo, Graphcore nhấn mạnh khả năng cung cấp điểm số cạnh tranh so với Nvidia ở mức giá thấp hơn cho các máy BowPOD với số lượng chip tăng tốc IPU khác nhau. Ví dụ, công ty đã chào hàng BowPOD256 của mình, có điểm số ở vị trí thứ năm trong nhận dạng hình ảnh ResNet, nhanh hơn gấp mười lần so với hệ thống Nvidia DGX 8 chiều, trong khi chi phí thấp hơn.
“Điều quan trọng nhất chắc chắn là tính kinh tế”, Matt Fyles, trưởng bộ phận phần mềm của Graphcore, cho biết trong một cuộc họp báo giới truyền thông. “Trước đây, chúng tôi từng có xu hướng máy móc ngày càng nhanh hơn nhưng đắt hơn, nhưng chúng tôi đã vẽ một đường thẳng trên cát, chúng tôi sẽ không làm cho nó đắt hơn.”
Cũng thế: Để đo lường AI năng lượng cực thấp, MLPerf lấy điểm chuẩn TinyML
Mặc dù một số máy Graphcore nhỏ hơn theo dõi điểm số tốt nhất hoặc Nvidia và Graphcore bằng một đoạn thời gian đào tạo, “Không khách hàng nào của chúng tôi quan tâm đến vài phút, điều họ quan tâm là liệu bạn có cạnh tranh được không và sau đó bạn có thể giải quyết vấn đề vấn đề mà họ quan tâm, “ông nói.
Fyles nói thêm, “Có rất nhiều dự án với hàng nghìn con chip, nhưng bây giờ ngành công nghiệp sẽ mở rộng những gì bạn có thể làm khác với nền tảng thay vì chỉ. Chúng tôi phải giành chiến thắng trong cuộc cạnh tranh điểm chuẩn này – đó là cuộc đua tới đáy . “
Như trong các báo cáo trước đây, Thiết bị Micro nâng cao có quyền khoe khoang đối với Intel. Bộ xử lý máy chủ EPYC hoặc ROME của AMD đã được sử dụng trong 79 trong số 130 hệ thống được nhập vào, một tỷ lệ lớn hơn so với chip Intel XEON. Hơn nữa, 33 trong số 40 kết quả hàng đầu trong tám bài kiểm tra điểm chuẩn là các hệ thống dựa trên AMD.
Như trước đây, Intel, ngoài việc có bộ xử lý XEON của mình trong các hệ thống đối tác, cũng đã thực hiện các mục nhập riêng của mình với đơn vị Habana Labs, sử dụng XEON kết hợp với chip tăng tốc Habana Gaudi thay vì GPU Nvidia. Intel chỉ tập trung nỗ lực vào bài kiểm tra ngôn ngữ tự nhiên BERT nhưng không vượt qua được top 5.
Cũng thế: Điểm chuẩn hiệu suất của ngành AI, MLPerf, lần đầu tiên cũng đo lường năng lượng mà máy học tiêu thụ
Bảy trong số tám bài kiểm tra điểm chuẩn đều giống với cuộc thi tháng 12. Một mục mới là mục thay thế cho một trong các nhiệm vụ phát hiện đối tượng, trong đó máy tính phải phác thảo một đối tượng trong ảnh và gắn nhãn vào đường viền xác định đối tượng.
Trong phiên bản mới này, tập dữ liệu COCO và mạng nơ-ron SSD được sử dụng rộng rãi đã được thay thế bằng tập dữ liệu mới, OpenImages và mạng nơ-ron mới, RetinaNet.
OpenImages sử dụng các tệp hình ảnh cao hơn 1.200 x 1.600 pixel. Nhiệm vụ phát hiện đối tượng khác vẫn sử dụng COCO, sử dụng hình ảnh có độ phân giải thấp hơn, 640 x 480 pixel.
Trong cuộc họp báo trên phương tiện truyền thông, Kanter của MLCommons giải thích rằng tập dữ liệu OpenImages được kết hợp với một mạng nơ-ron điểm chuẩn mới cho người gửi sử dụng. Mạng trước đây dựa trên mạng nơ-ron ResNet cổ điển để nhận dạng hình ảnh và phân đoạn hình ảnh.
Giải pháp thay thế được sử dụng trong thử nghiệm mới, được gọi là RetinaNet, cải thiện độ chính xác thông qua nhiều cải tiến cho cấu trúc ResNet. Ví dụ: nó thêm cái được gọi là “kim tự tháp tính năng”, xem xét tất cả các giao diện của bối cảnh xung quanh một đối tượng, trong tất cả các lớp của mạng, thay vì chỉ một lớp của mạng, bổ sung ngữ cảnh để kích hoạt tốt hơn sự phân loại.
Cũng thế: Nvidia thực hiện quét sạch điểm chuẩn dự đoán MLPerf cho trí tuệ nhân tạo
Kanter cho biết: “Kim tự tháp đặc trưng là một kỹ thuật từ thị giác máy tính cổ điển, vì vậy, đây là một phần nào đó khác biệt với cách tiếp cận cổ điển được áp dụng trong lĩnh vực mạng nơ-ron”.
Ngoài kim tự tháp tính năng, kiến trúc cơ bản của RetinaNet, được gọi là ResNeXt, xử lý sự phức tạp với một cải tiến mới trên ResNet. Classic ResNet sử dụng cái được gọi là “phức hợp dày đặc” để lọc các pixel theo chiều cao và chiều rộng của hình ảnh cũng như các kênh RGB. ResNeXt chia các bộ lọc RGB thành các bộ lọc riêng biệt được gọi là “các khối chập được nhóm”. Những nhóm này, hoạt động song song, học cách chuyên môn hóa các khía cạnh của kênh màu. Điều đó cũng góp phần mang lại độ chính xác cao hơn.
Cũng thế: Google, Nvidia quảng cáo về những tiến bộ trong đào tạo AI với kết quả điểm chuẩn MLPerf
Cũng thế: Kết quả điểm chuẩn MLPerf cho thấy thời gian đào tạo AI hàng đầu của Nvidia




