Guest essay by Eric Worrall
The reinforcement learning of deep intelligence AI has demonstrated greater control over fusion plasmas, the scientists claim. But they may also have inadvertently revealed a fatal weakness in their approach.
DeepMind trained an AI to control nuclear fusion
The Google-backed company taught a reinforcement learning algorithm to manipulate the fiery plasma inside a tokamak nuclear fusion reactor.
AMIT KATWALASCIENCE February 16, 2022 11:00 am
THE INSIDE OF the tokamak — the donut-shaped vessel designed to house nuclear fusion — exhibits a special kind of chaos. Hydrogen atoms are smashed together at unpredictably high temperatures, creating a whirling plasma, hotter than the surface of the sun. Finding clever ways to control and limit that plasma will be the key to unlocking the potential of nuclear fusion reaction, which has been promoted as the clean energy source of the future for decades. At this point, the fundamental fusion of science seems plausible, so what remains is an engineering challenge. “We need to be able to heat this matter and hold it together long enough for us to get the energy out,” said Ambrogio Fasoli, Director of the Swiss Plasma Center at the École Polytechnique Fédérale de Lausanne in Switzerland. from it.
That’s where DeepMind comes in. The artificial intelligence company, backed by Google’s parent company Alphabet, previously moved to video games and proteinurgentand is working on a joint research project with the Swiss Plasma Center to develop an AI to control nuclear fusion.
…
DeepMind has developed an AI that can control plasma autonomously. ONE paperpublished in a magazine nature describes how researchers from two groups taught a deep reinforcement learning system to control 19 coils from within the TCV, variable configuration tokamak at the Swiss Plasma Center, used to carry out the research. The study will inform the design of larger fusion reactors in the future. “AI, and reinforcement learning in particular, is particularly well suited to the complex problems of manipulating plasma in tokamak,” said Martin Riedmiller, control group leader at DeepMind.
…
Read more: https://www.wired.com/story/deepmind-ai-nuclear-fusion/
The abstract of the article;
Magnetic control of tokamak plasmas through deep reinforcement learning
Jonas Degrave, Federico Felici, Martin Riedmiller
Show Authors
abstract
Nuclear fusion using magnetism, especially in the tokamak configuration, is a promising path towards sustainable energy. The core challenge is shaping and maintaining the high-temperature plasma inside the tokamak vessel. This requires high-frequency, closed-loop control using magnetic drive coils, further complicated by the diverse requirements across a wide variety of plasma configurations. In this work, we introduce a previously not described architecture for tokamak magnetic controller design that automatically learns to command the entire control coils. This architecture meets specified control goals at a high level, while meeting physical and operational constraints. This approach offers unprecedented flexibility and generality in problem specification and significantly reduces the design effort to create new plasma configurations. We successfully manufacture and control a wide range of plasma configurations on Tokamak à Configuration Variablesfirst,2, which includes regular, stretched shapes, as well as advanced configurations, such as negative triangle and ‘snowflake’ profiles. Our approach helps to accurately track position, current, and shape for these profiles. We also demonstrate stable ‘droplets’ on the TCV, where two separate plasmas are simultaneously maintained in the vessel. This represents a remarkable step forward for tokamak feedback control, demonstrates the potential of reinforcement learning to accelerate research in the fusion field, and is one of the most challenging real-world systems that have ever been encountered. reinforcement learning was applied.
Read more: https://www.nature.com/articles/s41586-021-04301-9
What is this important weakness that I mentioned?
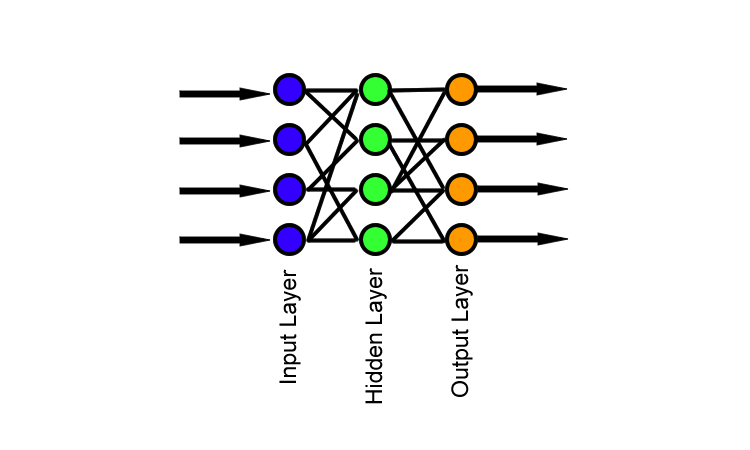
The Deep Mind is an extremely powerful AI. But thanks to its architecture, the Deep Mind system is stateless. It has no memory of the past.
Deep Mind accepts an input, like the current state of the reactor. It handles input. Then it gives an output and forgets everything it just did. Every day is the first day of Deep Mind.

This is good when playing a game of chess, because it is possible to gauge the current state of the board and make a technically perfect move. Chess AI doesn’t need to know the past, all it has to do is evaluate the present and decide the best move based on the current layout of the pieces.
This model of living in the moment starts to break down as you try to control real-world processes.
Imagine you are trying to train an AI to catch a baseball, by showing robot pictures of the field. You cannot catch the ball by moving the robot arm to the position of the ball, you have to intercept the ball in flight, by predicting the position of the ball in the time it takes to bring the robot arm to the correct position. This requires not only knowledge of the ball’s current position, but also the ability to judge the ball’s flight path, velocity, and direction in which it is traveling. This is knowledge that a robot can only acquire by memorizing the position of the ball, the speed and direction it moves to its current position.
Only knowledge of the past can give a robot the ability to actually manage a real-world process.
I’m not dissecting what Google and the Swiss Plasma Center have achieved – they’ve proven that AI has a role to play in the management of unified plasmas. What I’m wondering is whether a deep mind reinforcement learning architecture is the best solution.
Because there is another layer of AI architecture that can learn from their mistakes just like Deep Mind, but can also evolve to have a memory of the past. For example, NEAT, or Neuroevolution of Enhanced Topologies.
Unlike Deep Mind-style architectures, which have a finite, well-defined path from stimulus to response, then the neural network forgets everything until presented with a new stimulus, the NEAT system is very messy. They develop their own network of connections, even adding new neurons and layers if needed, which can include backflow connections. A signal can enter the NEAT network and bounce back, affecting the process, never really being forgotten until the information is no longer relevant. Unlike Deep Mind, the NEAT network can respond differently to the same stimuli, depending on the NEAT network’s memory of the past. NEAT can catch baseball.
But the NEAT-style architecture doesn’t fit Google’s AI business model.
Stateless neural network AI architectures are much easier to manage from a business perspective, they allow Google to create vast arrays of independent computers that are all perfect copies of each other and only specify the next input processing request, the next plasma sensor reader, to any computer in their array.
In contrast, the NEAT system needs a dedicated computer. If a particular NEAT solution has a feedback loop, the current state is important. The current state of the NEAT network cannot be erased once the task is completed, and to be rehydrated back to its original state on any available computer, it must remember what happened before.
In Google’s world, this would be an absolute nightmare – each customer would need their own dedicated computer. This will completely mess up their business model, because if the trial ends, customers won’t necessarily tell Google they don’t need a dedicated computer anymore. Assigning dedicated computers will increase resources, depleting the computer resources available to other clients.
That state, or the current state of the NEAT network, would have to be saved somewhere and routed across the Google network – this would require a significant increase in storage and network capacity, compared to what is needed for the model Google’s current stateless business.
It will be interesting to see how far Google can implement their stateless Deep Mind model when it comes to process control. I’m impressed they made it work. Perhaps they simulated hold somehow, by having the client remember previous results and pass those results back to their network.
Or perhaps plasmas are almost like a chessboard – most of the time, the current state of the plasma is enough information to calculate the next step needed to maintain control.
But Google’s Deep Mind experiment wasn’t completely successful. I suspect that the final missing piece will be to reject Deep Mind’s stateless architecture and embrace a neural network architecture that can catch baseball.
The simulated state, in which humans try to guess what memory of the past is needed to catch a baseball, cannot compare with the flexibility of a NEAT-style neural network architecture that can develop memories about their own past, which is capable of making a mind of itself about the state it must hold to perform its task and how long that state remains relevant.